-
-
手机阅读
摘要:研究了利用盲源分离理论解决语音识别之前的语音净化问题。基于MSICA算法良好的性能、低复杂度和实时性,设计了以TI公司的TMS320C6416数字信号处理器为内核的语音净化系统。该系统可以使语音识别系统获得纯净语音,从而有效提高语音识别系统的识别率和鲁棒性。
关键词:盲源分离 DSP 语音识别 语音净化
目前针对语音识别提出了很多算法,但是这些研究基本上都是基于较为纯净的语音环境,一旦待识别的环境中有噪声和干扰,语音识别就会受到严重影响。因为大多数语音识别的语音模板基本上是在无噪声和无混响的“纯净”环境中采集、转换而成。而实现环境中不可避免地存在干扰和噪声,包括其他人的声音和回声等,这些噪声有时很强,使语音识别系统的性能大大降低甚至瘫痪。已有的信号去噪、参数去噪和抗噪识别等方法都有一定的局限。如果能实现噪声和语音的自动分离,即在识别前就获得较为纯净的语音,可以彻底解决噪声环境下的识别问题。近年来取得很大进展的盲源分离为噪声和语音的分离提供了可能。盲源分离(Blind Source Separation)的算法众多且运算复杂,经比较,其中T.Nishikawa等人提出的分阶段ICA方法(MSICA)适合有混响的噪声环境中的语音分离问题。经过计算机仿真,MSICA算法分离一段7s的语音要用时10ms以上,计算机和低速的DSPs很难满足实时要求。针对这一算法,设计了一套以TI的TMS320C6416 DSP(简称6416)芯片为内核的语音净化系统。6416的时钟速度高达720MHz,经过使用MSICA算法的测试,该系统可以实时地对语音识别的信号进行净化处理,有效地提高语音识别系统的抗噪性和鲁棒性。
1 算法描述
1.1 语音识别信号的混合模型
1.1.1 卷积混合一般模型
语音信号的混合模型已从瞬时模型发展到卷积模型,相比瞬时模型而言卷积模型更接近真实环境。麦克风所测是卷积混迭信号,即源信号及其滤波与延迟的混迭信号的线性组合再加上其它噪声,如(1)式所示。

式(1)中,sj(t),j=1,…,N为信号源,且各源信号相互独立;xi(t),i=1,…,N为N个观测数据向量,其元素是各个麦克凤得到的输入。所以观测信号xi(t)是每个源信号sj(t)经过延时tij,并乘以因子aij(t)(冲击响应)后叠加,最后加上噪声ni(t)。
1.1.2 针对语音识别的简化混合模型
一般的语音识别只有一个麦克风,根据盲源分离理论,麦克凤数应不少于信源数,所以采用主副两个麦克风输入待识别语音,为简化处理假定只有主讲话者声音s1和背景噪声s2(此背景噪声包括经过延迟的回声)两个声源。可得如图1的混合模型。
信号源s1到达两个麦克风的时间间隔为t21,且幅度值不同;s2到达两个麦克风的时间间隔为t12,幅度值也不同。又因为主信号源s1非常靠近两个麦克风,所以认为T21比T12小很多,且趋于零。于是得到相应的模型表达式的简化形式:
x1(t)=s1(t)+a12s2(t-t12)+n1(t) (2)
x2(t)=a21s1(t-t21)+s2(t)+n2(t)
1.2 MSICA算法及其实现步骤
传统采用频域ICA(FDICA)或者时域ICA(TDICA)方法,单一的方法在真实环境中缺点很明显,分离效果在混响环境中受到很大影响。然而一种时频域结合多级分离的混合型ICA算法——MSICA算法可以有效解决这一问题。
该算法主要由三个步骤组成:首先,利用FDICA的高稳态性的优点在一定程度上分离源信号;为了简化后续计算,白化FDICA分离出来的信号;接着,把白化后的FDICA输出信号当作TDICA的输入信号,并用TDICA分离线留的交叉干扰分量;最后,TDICA的输出信号即为分离信号。算法框图如图2所示。
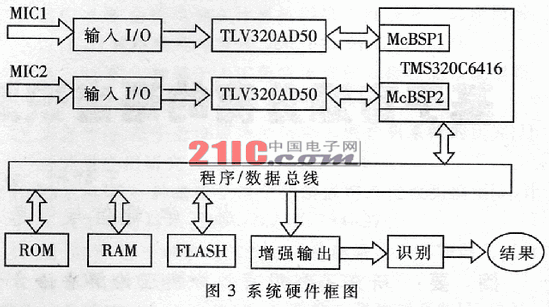
2 DSP硬件系统设计
2.1 硬件结构
为实现上述算法设计了DSP语音分离系统,该系统主要参数如下:
·TMS320C6416 DSP;
·16M words FLASH ROM;
·两个EMIF:64-Bit EMIFA和16-Bit EMIFB;
·133MHz的16MB SDRAM;
·两个16-bit立体声CODEC:TLV320AD50。

TMS320C6416有很高的信号处理能力以及丰富的片内存储咕嘟和片内外设,且有两级内部存储结构。第一级L1缓存包含各为16KB的程序和数据存储器,第二级L2包含1024KB的存储空间。第一级只能作为缓存而第二级可以被设置为部分静态RAM和部分缓存。在语音净化系统中,设置L2为4通道256KB缓存和768KB静态RAM。这种配置使用了最大允许的缓存,是因为MSICA算法将处理大量的数据,访问外部存储器会有瓶颈,而大缓存可以将诸如中断服务程序、常用函数的代码、软件堆栈等关键数据段和反复使用的系数存储于片内存储器中,从而大大提高内部存储空间的使用效率。6416的两个多通道缓冲串口(McBSP)用作数据的输入输出端口。模拟接口芯片TLV320AD50可以提供16bit的数/模、模/数转换,最大转换率是22.5kHz。采样率为8kHz,两个TLV320AD50分别通过McBSP与TMS320C6416相连。两路混合语音信号通过模拟接口电路转化为数字信号,两路数字信号通过TMS320C6416的两个McBSP输入,根据语音特征存储中存储的语音特征进行语音分离,分离出纯净的特识别语音,进行语音识别,最后输出识别结果。系统框图见图3。
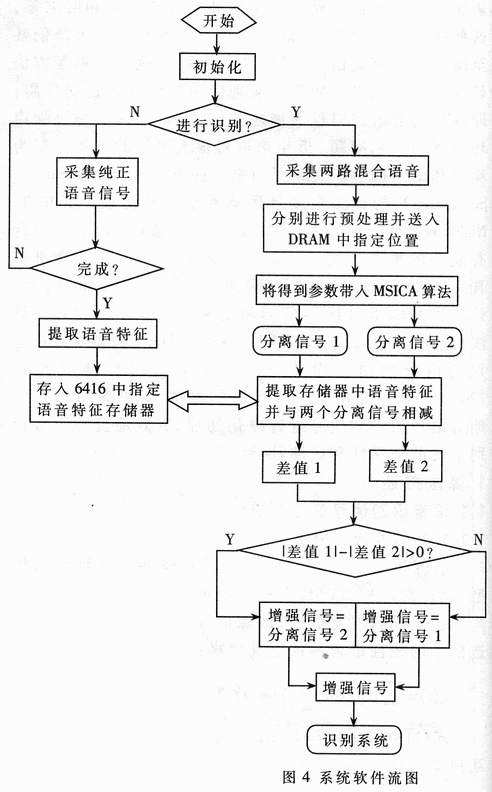
2.2 软件流程
系统上电后,存储在FLASH ROM中的程序将装入TMS320C6416的片内RAM中,程序对寄存器、中断向量表和编码进行初始化并对片内McBSP进行配置,完成这些初始化的任务后系统采集并处理语音信号。系统首先对目前状态进行辨识。开机后的状态分为非识别状态和识别状态,非识别状态 下系统将采集纯正语音信号,提取出语音特征送入存储器中作为模板;识别状态下首先参数考纯净语音的特征对采集的双路混合信号进行分离,获得纯净的待别语音,最后送入识别系统完成语音识别。整个流程见图4。
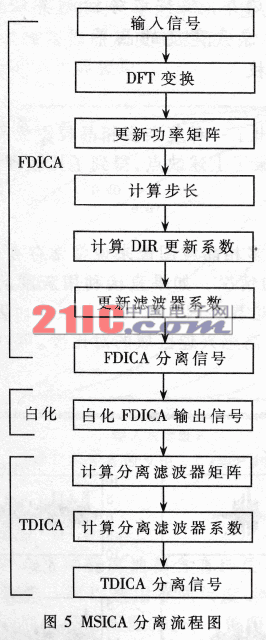
具体分离步骤在初始化之后,主函数程序进入一个等待循环,在一个新的采样输入被获取之后与中断服务程序(ISR)一起工作并调用分离程序。第一步,信号首先通过TI的DFT程序变换到频域。系统使用最前面的几个块(例如取5块)来估计输入信号x1和x2每个频率分量的功率矩阵。流程图(见图5)中的变量P表示正在处理的块数。对于接下来的每一块(P≥5),系统通过指数平均来更新输入信号的功率矩阵,以计算出梯度。然后计算步长u12、u21和差分脉冲响应滤波器ΔH12、ΔH21的更新系数。最后确定更新系统和DRIR滤波器系数,在频域对输入信号进行初步分离。第二步,白化程序对FDICA输出信号进行白化处理,以去除信号的相关性。第三步,首先通过最小化非负代价函数计算分离滤波器矩阵和分离滤波器系数,然后带入白化后的信号求得TDICA输出信号。
2.3 代码优化
为了进行实时的混合语音分离并识别,分离算法必须在尽可能短的时间(如1~2s)内完成。在本系统中,通过CCS对C源代码进行编译,并对分离算法的一些关键模块从内联函数替换、数据读写、循环体优化、函数拆并、C级优化等方面进行优化设计,以达到充分利用CPU、存储器等资源,提高算法运行速度,满足实时性要求。
(1)内联函数优化
通过内联函数替换提高代码性能。内联函数直接与汇编指令相对应,通过使用它们,C编译器能达到更好的编译效果,并充分利用系统资源。C6416提供丰富的内联函数,涵盖了各种数据类型的乘、加、移位等操作。实验结果表明,内联函数替换是提高代码性能最简单、直接有效的方法。
(2)数据读写优化
充分利用C6416的双字存储指信和packing/unpacking方式提高代码的运行速度。
(3)循环体优化
通过软件流水工具(Software Pipeline)适当安排循环指令,使多次迭代并行执行,以达到优化代码的目的。
(4)函数拆并优化
将某些大函数拆开成多个小函数或相反,以提高程序的运行速度。对FDICA和TDICA等大程序中某些常用的分支,可将其拆分以减少判断、跳转操作。对于某些简单的小函数,将其合并成大函数有助于减少程序调用开销。
(5)C级优化
在定点DSP上进行浮点运算会影响C源代码的性能。因此,第一个优化任务就是将源码中运算比较密集的部分(如分离滤波器矩阵和分离滤波器系数的计算)转换成定点的算法。此外,影响系统性能的一个重要原因是没有有效利用DSP的并行计算能力,TMS320C6416为最优化这些并行操作的打包数据处理提供了特殊的指令。系统另一个瓶颈是对外部存储器的访问。对混合语音的分离需要处理大量的数据,存储和访问可能是DSP系统的最大瓶颈。通过使用缓存可以缓解瓶颈,优化在外部和内部存储中的数据定位可以提高系统的性能。最后,使用C编译器的最优化选项编译代码。
上述的优化并非已经完全,在后续的研究中代码可以进一步优化,如可改进以下几处:首先,使用DMA以提高存储器访问的性能并减少存储器消耗;其次,为了避免浮点溢出可以将代码全部转换为定点,对代码中的关键循环进行更好的组织以实现软件流水线;最后,为了最大程序提高性能可以使用线性汇编语言并对部分代码进行汇编层的优化。
2.4 实验结果
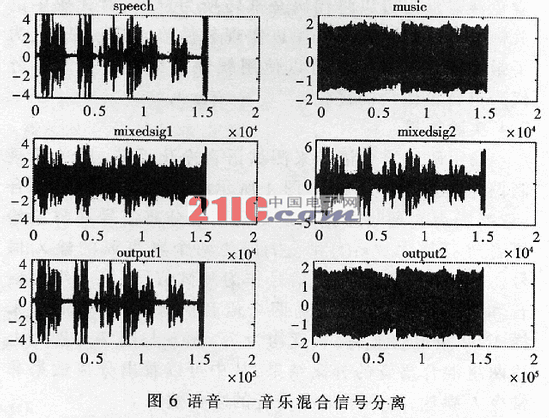
采用两组混合语音来测试,即单独录制两个纯净的信号源,图1所示模型用MATLAB混合(忽略噪声),通过净化系统得到两级分离信号并与原始语音进行比对。x1(t)和x2(t)即为两个麦克风的输入信号。使用以下两组声音信号作为测试信号,第一组为语音和音乐信号,第二组为两个语音信号,都是16kHz采样16bit单声道文件,长度均为7s。图6与图7分别为上述两组混合语音的分离结果,从中可以看出分离效果非常令人满意,达到了带噪语音的净化效果。

在实验室环境引入语音净化系统后,语音识别的速度虽然略有下降,但是识别语音的信噪比有显著提高,在有不同信噪比的音乐和混响噪声的背景中,识别率平均提高30%以上。